What Bugs Live in the Cloud? A Study of 3000+ Issues in Cloud Systems
本文探索了6个流行的云系统:Hadoop MapReduce, HDFS, HBase, Cassandra, ZooKeeper, Flume
分析了从2011年到2014年的21399个bug repositories,并分析了3655个”vital”的issue
本文为他们的工作命名为Cloud Bug Study database (CBSDB)
Introduction
可扩展的分布式系统有:
- scale-out computing frameworks
- distributed key-value stores
- scalable file systems
- synchronization services
- cluster management services
本文基本问题:
why are cloud systems not 100% dependable?
引申出的更多问题:
- Why is it hard to develop a fully reliable cloud systems?
- What bugs “live” in cloud systems?
- How should we properly classify bugs in cloud systems?
- Are there new classes of bugs unique to cloud systems?
- What types of bugs can only be found in deployment?
- Why existing tools (unit tests, model checkers, etc.) cannot capture those bugs prior to deployment?
- how should cloud dependability tools evolve in the near future?
本文从6个流行的云系统repo中提交的issue中收集vital的issue。对每个vital issue,本文分析了开发者对每个issue的回应,然后进行分类。
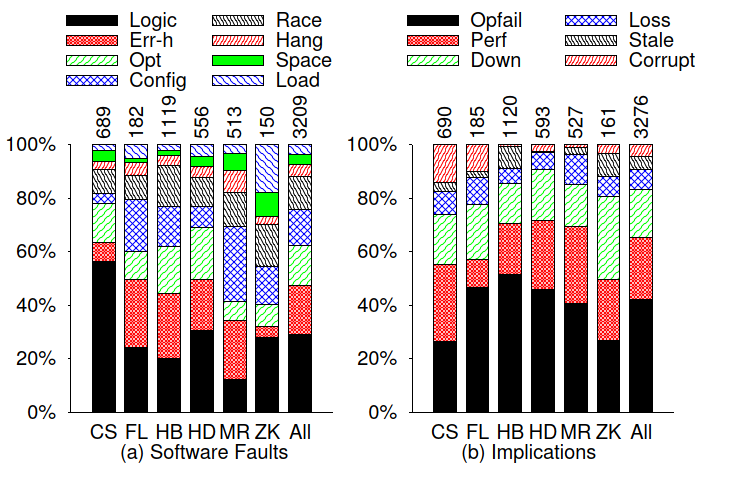
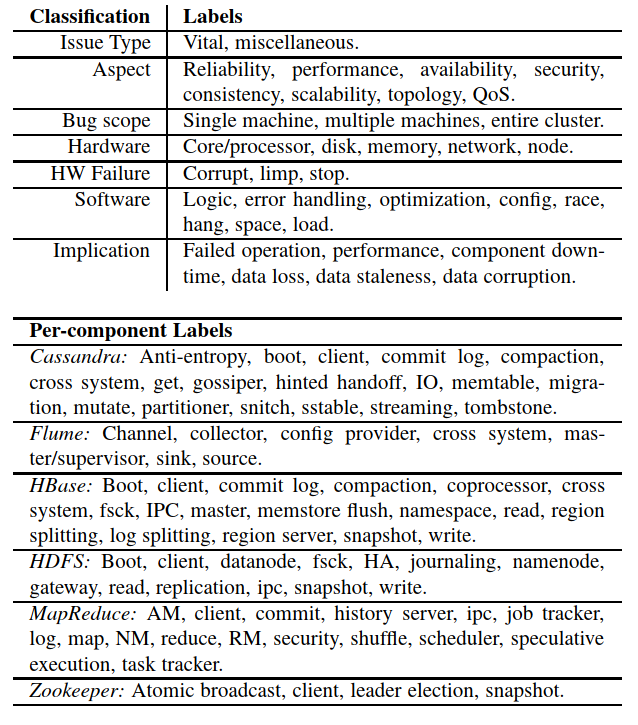
- 按照aspect分类
- reliability(45%)
- performance(22%)
- availability(16%)
- security
- data consistency(5%,云系统独有)
- scalability (2%,云系统独有)
- topology(1%,云系统独有)
- QoS
- killer bug
- hardware failures
- stop
- corrupt
- limp
- software bug types
- error handling(18%)
- optimization(15%)
- configuration(14%)
- data race(12%)
- hang(4%)
- space(4%)
- load(4%)
- logic bugs(29%)
- implication
- failed operations
- performance problems
- component downtimes
- data loss
- staleness
- corruption
本文的一个结论:cloud systems favor availability over correctness
Methodology
bug priority label: trivial, minor, major, critical, blocker
本文将前两个标记为minor,将后三个标记为major。本文主要分析major,即后三个
issue分类:基于issue type→ miscellaneous vs. vital
本文用到的一些缩写
- SPoF:single point of failure
- OOM:out-of-memory
- GC:garbage collection
- WAL:write-ahead logging
- DC:data center
- AM:application master
- NM:node manager
- RM:resource manager
- HA:high availiabilty
- CS:Cassandra
- FL:Flume
- HB:HBase
- HD:HDFS
- MR:MapReduce
- ZK:ZooKeeper
Issue Aspects
Data Consistency Aspect
数据一致性是指所有节点或副本都同意数据的相同值(或在最终的一致性的情况下同意)。
其中存在几种情况会违反一致性,包括:操作协议中的逻辑错误(43%),数据竞争(29%),故障处理问题(10%)
Buggy logic in operational protocols
除了主要的read/write协议,还有其他协议会接触并修改数据,比如bootstrap,cloning,fsck。这之中就会存在不一致的bug
例如Cassandra在进行bootstrap a node的操作时,应该根据每个密钥的一致性等级从多个邻居中获取必要数量的键值对replica,但是协议错误地只从一个最近的。邻居获取一个replica。
另一个跨DC同步协议中,压缩算法无法压缩某些键值对,无法捕获错误,但允许整个操作继续进行,在协议完成后,两个DC的视图保持一致,并保持沉默。
在HBase中,由于cloning操作中的连接问题,将克隆元数据,但不克隆数据,
Concurrency bugs and node failures
节点内数据竞争是造成数据不一致的主要原因。
节点间数据竞争也是主要原因。异步消息的复杂重新排序以及节点故障使系统进入错误状态,例如ZooKeeper的不同节点的已提交事务具有不同的视图。
Summary
与主要的协议一样,操作协议也能修改数据,但是它们没有经过足够的测试,因而时常能触发数据不一致错误。
发现的一个特点:很多云系统在出现数据不一致错误之后会继续运行,Availablity似乎比consistency更重要
Scalability Aspect
Scalability问题只占了2%,但是它们很难在小规模测试中被发现。
此类别中,software optimization(29%),space(21%)和load(21%)是主要原因。在影响方面,performance problems(52%),component downtimes(27%),和failed operations(16%)是主要问题。为了更深入了解问题,本文将Scalability问题分为4个轴:cluster size,data size,load和failure
Scale of cluster size
协议算法必须预期不同的cluster大小,但是就node数量而言,算法可以是平方或是立方。
例如Cassandra,当一个node更改其ring位置时,其他受影响的node必须执行复杂度为$\Omega(n^3)$的key-range重新计算。如果cluster中有100~300个node,这将导致CPU”爆炸”并最终导致node”崩溃”,需要通过手动调整重新启动整个集群
Elasticity通常没有经过彻底测试,系统管理员认为它们可以停用/重新启用任意数量的node,但这可能是致命的,这会带来额外负载的问题。
Scale of data size
云系统必须预见到大数据量,但通常不清楚限制是什么。
例如,在HBase中,由于无效的表查找操作,打开一个包含100K多个区域的大表会花费数十分钟。
类似地,在HBase中,相对于日志文件的数量,日志清理过程为$O(n^2)$。这个缓慢的过程导致HBase在处理传入请求方面落后。
本文还发现用户在大型数据集上提交查询导致服务器端OOM的情况。在这里,用户必须将大型查询分解为较小的部分。
Scale of request load
云系统有时无法满足各种大型请求负载。
例如,某些HDFS用户并行创建数千个小文件,从而导致OOM。HDFS不会这样,因为它以大文件为目标。在Cassandra中,用户会产生大量删除操作,这些删除操作会阻止其他重要请求。在HDFS中,当写入100,000个文件的作业被杀死时,HDFS经历了租赁恢复的爆发,这导致其他重要的RPC调用(例如,租赁更新和心跳)被丢弃。
Scale of failure
从规模上讲,大量组件可能同时发生故障,但是恢复通常是没有准备的。
例如,在MapReduce中,由于未优化与HDFS的通信,因此恢复16,000个失败的mapper(如果AM发生故障)将花费超过7个小时的时间。
在另一种情况下,当大量的reducer报告提取失败时,直到2小时(由于阈值错误)才重新启动任务。而且,当MapReduce遇到数千个任务失败时,会放大昂贵的$O(n^3)$恢复(三重for循环处理)。
在ZooKeeper中,当1000个客户端由于网络故障而同时断开连接时,session-close stampede事件会导致其他活动客户端由于心跳响应延迟而断开连接。
Summary
Scalability的问题在部署后期才会浮现。本文发现,主要的read/write协议往往很健壮,因为实时的用户工作负载始终在对其进行隐式的测试。操作协议(recovery,boot等)通常存在Scalability bug。因此,操作协议需要经常进行大规模测试。诸如松散耦合,分散,批处理和节流之类的通用解决方案很受欢迎,但有时还不够。有些问题需要修复特定邻域的算法。
Topology Aspect
有时候,在某些网络拓扑结构上,云系统的协议不能很好的工作,这被称为拓扑bug。这些拓扑bug在预部署中也无法发现。
Cross-DC awareness
近来,地理分布系统已经普及。在这种情况下,通信等待时间更长,因此异步是基本属性。但是某些协议本质上依旧是同步的,
例如,在HBase中,两个DC ping-pong 无限地复制请求,而在Cassandra中,由于两个DC之间的时间漂移,与时间有关的操作失败。
Rack awareness
本文发现了诸如恢复之类的操作协议不了解rack的情况。
例如,当一个mapper和一个reducer在一个带有不稳定连接的单独rack中运行时,MapReduce总是判断mapper node是问题所在(而不是网络),因此被列入黑名单。然后,MapReduce在同一rack中重新运行该mapper,最终rack中的所有节点都被错误地列入黑名单。
New layering architecture
随着云系统的成熟,其架构也在不断发展。这些体系结构更改并不总是在受影响的协议中进行适当的更改之后。
例如,在具有虚拟节点(vnode)的Cassandra中,cluster拓扑和规模突然发生变化(默认为256个vnode/计算机)但是许多Cassandra协议仍然采用物理节点拓扑,这会导致许多可Scalability问题(例如,gossip协议无法处理gossip消息数量级的增加)。
在HDFS中,节点组导致协议中的许多更改,例如故障转移,平衡,复制和迁移。
summary
用户期望云系统可以在许多不同的拓扑结构上正常运行(即,不同数量的节点,机架和数据中心,具有不同的网络条件)。
与拓扑相关的测试和验证仍然是最少的,应该成为未来云可靠性工具的重点。
另一个重点是,与拓扑相关的体系结构的更改通常不会直接跟在受影响协议的更改上。
QoS Aspect
QoS是多租户系统的基本要求。
Horizontal/intra-system QoS
关于繁重的操作存在许多影响其他操作的问题,开发人员可以使用经典技术快速解决这些问题,例如准入控制,优先级划分和限制。但是,在一个协议中引入阈值时必须小心,因为它可能会对其他协议产生负面影响。
例如,在HDFS中,在流传输级别进行限制会导致请求在RPC层排队。
Vertical/cross-system QoS
这是QoS的最大挑战。开发人员只能控制自己的系统,但是可堆叠的云系统需要端到端QoS。
例如,HBase开发人员提出了有关如何在HDFS或MapReduce层转换HBase的QoS的问题。而且,诸如节流之类的一些技术难以一直强制到操作系统级别(例如,磁盘QoS涉及许多度量,诸如带宽,IOPS或等待时间)。还讨论了缺乏控制对QoS准确性的影响(例如,当开发人员无法控制Java GC时,很难保证QoS)。
Summary
Horizontal QoS更容易保证,因为只涉及一个系统。云系统必须检查一种协议中的QoS实施是否对其他协议没有负面影响。
Vertical QoS则难以确保,开发人员没有端到端控制,并且没有提出很多跨系统QoS抽象。此外一个日益严峻的挑战是,很多开源云系统没有考虑QoS。
Killer Bugs
通过研究大型系统的问题,本文研究了所谓的“Killer Bugs”,即同时影响多个节点甚至整个集群的错误。这项特殊的研究非常重要,因为尽管”no-SPoF”原则已在云社区中广泛宣讲,但研究表明SPoF仍然以多种形式存在。
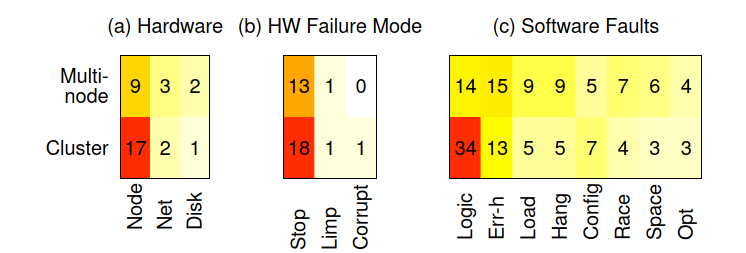
Positive feedback loop
在这种情况下会发生故障,然后开始恢复,但是恢复会引入更多的负载,从而导致更多的故障。
例如,在Cassandra中,八卦流量会显着增加,从而导致群集在数小时内不稳定。由于活动节点被错误地宣布为死节点,因此管理员或弹性工具可能会向群集中添加更多节点,从而导致更多的gossip流量。云系统应该更好地识别正反馈回路。
Buggy failover
no-SPoF的关键是检测故障并执行故障转移。但是,如果故障转移代码本身是错误的,则此类保障将失效。
例如,在HBase中,当元数据区域服务器的故障转移出错时,由于无法访问整个集群元数据(META和ROOT表),整个集群将停止工作。
类似地,在HAHDFS中,当到备用名称节点故障转移中断时,所有数据节点将变得不可访问。
深入的分析表明,当故障转移遇到另一个故障时,故障转移代码中的错误就会浮现。简单地说,故障转移中的故障转移是脆弱的。
当受影响的组件是SPoF(例如主节点、元数据表)时,错误故障转移是一个致命的错误。
Repeated bugs after failover
no-SPoF的另一个关键是,在成功进行故障转移之后,系统应该能够恢复先前失败的操作。这对于机械故障是对的,但是对于软件错误则不正确。
如果故障转移后系统必须再次运行相同的错误逻辑,则整个过程将重复,并且整个cluster最终将消失。
例如,在HBase中,当区域服务器由于对损坏的区域文件的错误处理而死机时,HBase将故障转移到另一台运行相同代码并且也将死机的活动区域服务器。
A small window of SPoF
no-SPoF的另一个关键是确保始终准备好故障转移。
本文发现,一些操作任务被轻易禁用了故障转移机制。
例如,在ZooKeeper中,在动态集群重新配置期间,将禁用心跳监视,并且如果leader此时挂起,则无法选择新的leader。
Buggy start-up code
启动大型系统通常是一项复杂的操作,如果启动代码失败,则所有机器将无法使用。
例如,ZooKeeper领导者选举协议容易出错,并且不会导致选举任何领导者。没有领导者,ZooKeeper集群将无法工作。同样,我们发现了HDFS名称节点启动协议的问题。
Distributed deadlock
例如,在Cassandra启动过程中,所有node在gossip时都可能永远不能进入正常状态。这种死锁也发生在其他Cassandra协议中,例如迁移和压缩,并且通常是由消息重新排序,网络故障或软件错误引起的。
分布式死锁也可能由”静默挂起”引起。例如,在HDFS中,一个节点上的磁盘挂起会导致整个写入管道挂起。
Scalability and QoS bugs
Scalability和QoS bug也可能影响整个集群。
Hardware Issues
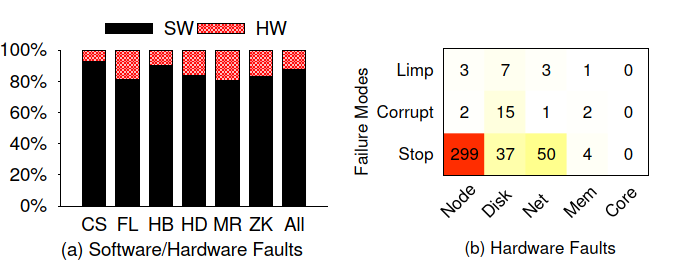
Fail-stop
云系统配备了各种机制来处理fail-stop。故障停止恢复之所以不容易,有几个原因。
- 交错的事件和故障(例如,节点上下故障,消息重新排序)可能会迫使系统进入意外状态。
- 使用协调服务(例如,HBase中使用ZooKeeper)并不能简化问题(例如,许多跨系统问题)。
- 经常无法正确处理一系列多重故障,并且可能发生大规模故障。
Corruption
众所周知,硬件会损坏数据,因此部署了端到端checksum。
但是本文发现了检测正确但是恢复不正确的情况。
例如,HDFS的恢复意外删除了健康的副本而保留了损坏的副本。
软件错误还会使数据的所有副本损坏,从而使端到端校验和不相关。
本文还发现一种有趣的情况,其中不良的硬件会生成错误警报,从而导致正常文件被标记为损坏并触发不必要的大数据恢复。
Limp Mode
好的硬件可以成为limpware。
本文发现云系统尚未准备好处理limpware的情况。
例如,HDFS假定磁盘I / O最终将完成,但是当磁盘降级时,名称节点的仲裁可能会挂起。
在HBase部署中,开发人员发现存储卡仅以正常速度的25%运行,从而导致积压,OOM和崩溃。
Software Issues
Error Handling
硬件和软件都可能发生故障,因此错误处理代码是必需的。
但是众所周知,错误处理代码会引入复杂性,并且容易出现错误。
Error/failure detection
在处理故障之前,首先要检测出故障,但是故障检测并不是完美的。
首先,错误通常会被忽略。例如,被忽略的Java异常。
其次,错误通常会被错误地检测到。例如
- 在HDFS协议中,网络故障被认为是磁盘故障,它会触发大量check-disk storm。
- 在HDFS写管道中,很难确定哪个节点有问题。
- 在MapReduce中,映射器和化简器之间的不良网络被错误地标记为地图节点的故障。
异步协议中的故障检测取决于超时。
如果超时时间太短,则可能导致误报。例如,高负载下的节点被视为已死,从而导致不必要的replication storm。
如果超时时间太长,某些操作会挂起。
一个更复杂的问题是跨系统超时。例如,在HDFS中10分钟后或在HBase中30秒后,一个节点被声明为死亡; 这种差异会导致HBase出现问题。一种解决方案是让多个层共享同一个故障检测器,但这在不同的软件开发人员群体之间可能很难实现。
Error propagation
检测到错误后,可能需要将该错误传播到上层并由上层处理。在分层系统中可能出现错误传播的问题。
例如,对于某些操作,HBase依靠HDFS来检测低级错误并通知HBase。但是,如果HDFS不这样做,则HBase会挂起。
Error handing
将错误信息传播到正确的层或组件后,必须进行正确的故障处理。
本文发现故障处理可能是“混乱的”(例如,在系统进入某些极端情况时不知道要做什么),非最佳的(例如,不了解拓扑),粗粒度的(例如,磁盘故障会导致整个带有12个磁盘的节点退役) ,并且会尽力而为,但不能100%正确(例如,为了推迟停机时间,如果数据磁盘已死且提交磁盘处于活动状态,则Cassandra节点将保持活动状态)。
Configuration
Wrong configuration
设置配置可能是一个棘手的过程。
例如,用户提供错误的输入,升级期间意外删除配置设置,云系统从静态在线配置转变为动态在线配置时的向后兼容性问题,OS兼容性问题以及不适用于某些工作负载的错误值。
配置问题可能导致数据丢失和损坏。
在MapReduce中,用户可以在不发出系统警告的情况下意外地为多个作业设置相同的工作目录。 Reducers的中间文件在合并期间可能会冲突,因为输出文件不是唯一的。在Flume中,行长度限制中的一个简单错误可能会导致消息损坏。
Multiple configurations
随着用户要求更多的控制,随着时间的推移会添加更多的配置参数,这意味着会导致更多的复杂性。不了解多个参数的相互作用可能是致命的。
例如,HBase管理员禁用WAL选项,并假定内存中的数据将定期刷新到磁盘(但是,禁用WAL时,HBase不会这样做)。
Data Races
数据竞争是任何并发软件都会存在的基本问题。云系统不仅会遭遇本地的并发错误(例如,线程交织),还会遇到分布式并发错误(例如,异步消息的重新排列)。

Hang
在软件工程中,挂起通常归因于死锁,但是,云开发人员具有更广泛的挂起含义。尤其是,预期操作时间很短但是实际上花费了很长时间才完成的操作被认为是挂起。
Silent hangs
超时{这里应该是指超时检测程序}通常部署在可能会挂起的操作周围(例如,网络操作)。但是,由于大型代码库的复杂性,某些可能挂起的系统组件有时会被忽略(即Timeoutless)。
例如,MapReduce开发人员没有为挂起的AM部署超时,但是他们意识到AM非常复杂,并且可以挂起的原因很多,例如RM异常,数据竞争,failing task和OOM。
本文工作还发现很少情况下的”虚假心跳”。节点通常具有心跳线程和几个工作线程。即使某些工作线程正在挂起,有故障的心跳线程仍可以报告良好的心跳,从而导致静默挂起。这表明心跳与实际progress之间的关系可能存在漏洞。
Overlooked limp mode
如前所述,硬件可以表现为limp模式。尽管在许多情况下,开发人员会预料到这一点(例如,网络速度变慢)并部署超时(主要是围绕主要协议),但仍有一些协议被忽略了。
一个主要的例子是MapReduce中的作业资源本地化,它不受推测执行的约束。在这里,当作业通过降级的网络下载大型JAR文件时,不会发生超时和故障转移。
Unserved tasks
挂起还可以定义为节点处于活动状态,但任务永远保留在队列中并且永远不会执行的情况。本文工作多次发现这种情况,这主要是由于深度数据竞争和逻辑错误导致的,这些错误极端情况能导致系统无法执行故障转移。
例如,在MapReduce中,任务可能会卡在“ FailContainerCleanUp”阶段,阻止任务在其他地方重新启动。
Distributed deadlock
如前所述,该问题会导致整个cluster挂起。
Space
Big data cleanup
大量旧数据很容易占用空间并需要快速清理。云系统必须定期清除各种大的旧数据,例如旧的error日志,提交日志和临时输出。
在许多情况下,清理过程仍然是由管理员手动完成的。如果不及时处理,那么狭窄的空间可能会导致性能问题或停机。
Insufficient space
作业/查询可以读取/写入大量数据。本文发现在没有可用内存的情况下许多作业会失败或在执行过程中挂起的情况。大作业不会自动切片,因此用户必须手动切片。
Resource leak
资源泄漏是不良空间管理的一种形式。
本文工作观察到各种泄漏,例如内存,套接字,文件描述符和特定于系统的泄漏(例如,流)。
在许多情况下,恢复期间会发生泄漏(例如,恢复后未关闭套接字)。
令人惊讶的是,内存泄漏发生在”基于Java”的云系统中。事实证明,开发人员不喜欢Java GC,而是决定直接通过C malloc或Java字节缓冲区来管理内存,但是粗心的内存管理会导致内存泄漏。
Load
Java GC
负载密集型系统导致频繁的内存分配/重新分配,从而迫使Java GC频繁运行。
问题在于Java GC每GB堆可以暂停8-10秒, 具有大内存的高端服务器可能会暂停几分钟。开发人员通过手动内存管理(例如,使用C malloc或Java字节缓冲区)解决了这一问题。这样可以提供稳定的性能,但也可能导致内存泄漏。
Beyond limit
很多时候,即使负载超出限制,云系统也会尝试满足所有请求。这可能会导致backlogs和OOM之类的问题,从而使系统崩溃,无法满足任何请求。云系统最好了解它们的限制并在过载时拒绝请求。
Operational loads
在没有Horizontal QoS的情况下,请求和操作负载可能会使其他重要操作陷入困境。
例如,许多情况下错误日志记录会创建大量磁盘写操作,从而降低主要操作的性能。这类问题主要是在部署中发现的,可能是因为很少对高负载的服务器进行操作协议的测试。
Implications
如果系统试图确保仅在一个轴上的可靠性(例如,没有数据丢失),则系统必须部署所有能够发现所有软件故障类型并确保所有硬件故障处理的正确性的错误查找工具。 建立高度可靠的云系统似乎是一个遥远的目标。
Other Use Cases of CBSDB
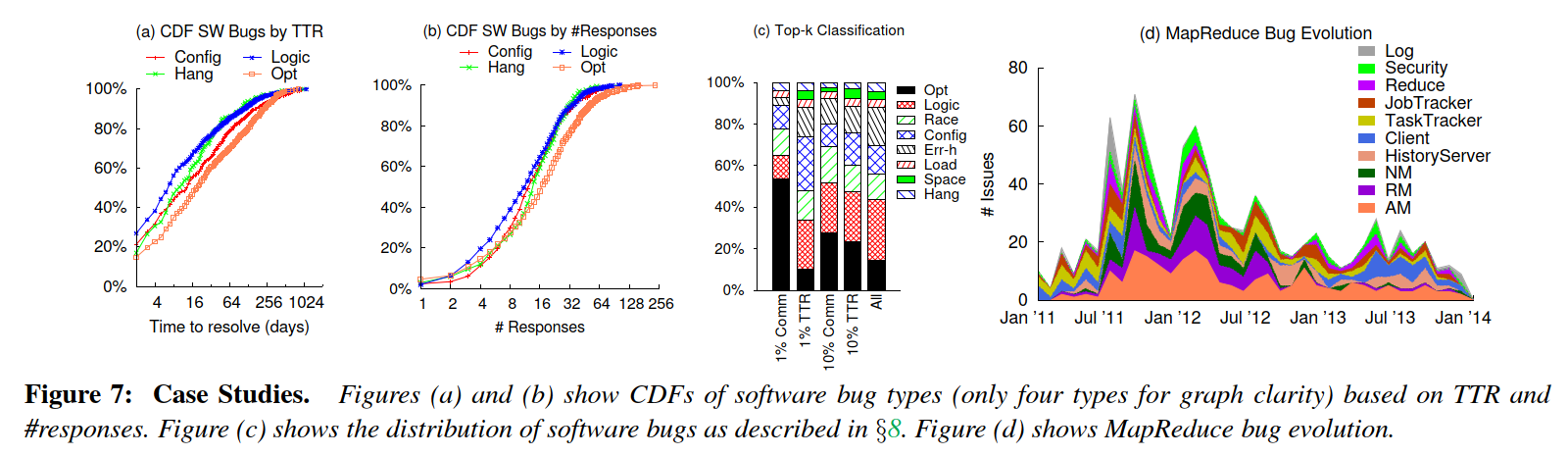
Longest time to resolve and most commented
原始的错误存储库包含数字字段,例如解析时间(TTR)和开发人员响应的数量,当与注释结合使用时,可以进行强大的分析。
上图a和b,可以回答以下问题:“哪些软件错误类型需要最长/最短的时间来解决,或者响应次数最多/最少?”
Top 1% or 10%
使用先前分析中的CDF,可以进一步得出另一项经验分析,上图c可以回答以下问题:“在大多数响应(或最长解决时间)问题的前1%(或10%)中,软件缺陷类型的分布是什么?” 有趣的是,在响应次数最多的前1%的错误中,优化问题覆盖了超过50%的问题,而在响应时间最长的前1%的问题中,仅覆盖了10%。
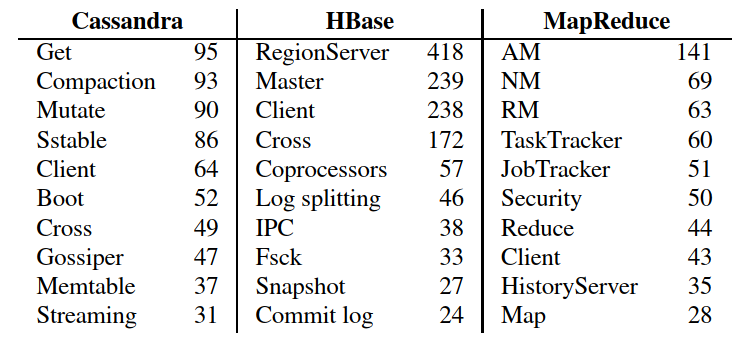
Per-component analysis
如上表,本文工作为每个系统添加了组件标签。这些标签回答了”哪些组件具有重要的问题计数”之类的问题很有用?”
下表中的经验数据可以帮助回答这个问题。可以看到跨系统问题(“cross”)在我们的目标系统中非常普遍。
Bug evolution
CBSDB用户还可以分析bug的演化。
个人笔记
非技术性工作,做了一些归纳和总结。
总结的还不错,内容清晰。
根据issue来总结分类,是一种方法,但是给人一种没有很系统的进行分析研究的感觉。换句话说,这个分类,很可能漏了一些情况,这些隐藏的漏洞可能触发几率小,或是影响不易受人察觉。
遗憾没什么技术相关内容。