DeepXplore: Automated Whitebox Testing of Deep Learning Systems
SOSP 2017
Kexin Pei (Columbia University); Yinzhi Cao (Lehigh University); Junfeng Yang, Suman Jana (Columbia University)
Abstract
深度学习(DL)系统越来越多地部署在对safety和security至关重要的领域中,包括无人驾驶汽车和恶意软件检测,在这些领域中,针对极端情况输入(corner case input)的系统行为的正确性和可预测性至关重要。现有的DL测试在很大程度上依赖于手动标记的数据,因此通常无法揭示罕见输入(rare inputs)的错误行为。
本文设计,实施和评估DeepXplore,DeepXplore是用于系统测试 real-world DL系统的第一个白盒框架。首先,本文介绍了神经元覆盖率(Neuron Coverage),用于系统地度量由测试输入执行的DL系统的各个部分。接下来,利用多个具有相似功能的DL系统作为cross-referencing oracles来避免手动检查。最后,演示了如何找到同时触发许多不同行为并实现高神经元覆盖率的DL系统的输入,可以将其表示为联合优化问题,并使用基于梯度的搜索技术有效解决。
DeepXplore在最新的DL模型中有效地发现了数千种不正确的极端情况行为(例如,无人驾驶汽车撞到护栏以及伪装成良性软件的恶意软件),并且在包括ImageNet和Udacity自动驾驶挑战在内的五个流行数据集上训练了成千上万的神经元数据。对于所有经过测试的DL模型,平均而言,DeepXplore生成了一个测试输入,表明仅在一台商用笔记本电脑上运行时,在一秒钟之内就表现出错误的行为。本文进一步证明,由DeepXplore生成的测试输入还可用于重新训练相应的DL模型,从而将模型的准确性提高多达3%。
1 Introduction
DL技术的广泛采用提出了新的挑战,因为此类系统的可预测性和正确性至关重要。不幸的是,尽管DL系统具有出色的功能,但由于一些原因(例如训练数据有偏差,模型的过拟合和欠拟合),经常会在极端情况下显示出意外或不正确的行为。在对safety和security至关重要的环境中,这种不正确的行为可能导致灾难性后果。例如,最近有一辆Google自动驾驶汽车撞上了一辆公共汽车,因为它希望公共汽车在一系列罕见的条件下能够避让,但公共汽车却没有。特斯拉的自动驾驶汽车撞向了拖车,因为自动驾驶系统由于“明亮的天空对比下的白色”和“高行驶高度”而无法将拖车识别为障碍物。这样的极端案例不是Google或Tesla的测试集的一部分,因此在测试期间从未出现过。
因此,像传统软件一样,对safety和security至关重要的DL系统必须针对不同的极端情况进行系统测试,以理想地检测和修复任何潜在的缺陷或不良行为。这就提出了一个新的系统问题,因为在具有上千个神经元和数百万个参数的大规模,真实世界的DL系统中对于所有极端情况的自动化系统性测试非常具有挑战性。
测试DL系统的标准方法是收集并手动标记尽可能多的真实测试数据。一些DL系统(例如Google无人驾驶汽车)也使用仿真来生成综合训练数据。
但是,这种模拟是完全无指导的,因为它没有考虑目标DL系统的内部。因此,对于现实世界中的DL系统的大输入空间(例如,无人驾驶汽车的所有可能路况),这些方法都没有希望能覆盖所有可能的极端案例中的很小一部分(如果有的话)。
对抗性深度学习的最新工作已经证明,通过在现有图像上添加最小扰动来精心制作的合成图像可以蒙蔽最先进的DL系统。关键思想是创建合成图像,以使DL模型对合成图像的分类与原始图片不同,但在人眼中仍然看起来相同。尽管此类对抗性图像暴露了DL模型的某些错误行为,但这种方法的主要限制在于,它必须将其扰动限制为微小的无形变化,或者需要手动检查。而且,就像现有DL测试的其他形式一样,对抗性图像仅覆盖DL系统逻辑的一小部分(52.3%)。实质上,当前用于发现不正确的极端情况的机器学习测试实践类似于通过使用代码覆盖率较低的测试输入来查找传统软件中的错误,因此不太可能发现许多错误的情况。
大型DL系统的自动化系统测试存在双重的关键挑战:
- 如何生成触发DL系统逻辑不同部分并发现不同类型错误行为的输入
- 如何识别DL系统的错误行为,且无需人工标记/检查。
本文介绍了如何设计和构建DeepXplore来应对这两个挑战。
首先,本文介绍了神经元覆盖率的概念,该概念用于根据输入激活的神经元数量(即输出值高于阈值)来测量一组测试输入所执行的DL系统逻辑的各个部分。在较高的层次上,DL系统的神经元覆盖率类似于传统系统的代码覆盖率,这是一种标准的经验指标,用于测量传统软件中输入所执行的代码量。但是,代码覆盖率本身并不是评估DL系统覆盖率的好指标,因为DL系统中的大多数规则与传统软件不同,不是由程序员手动编写的,而是从训练数据中学习的。实际上,本文发现,对于本工作测试的大多数DL系统,即使单个随机选择的测试输入也能够实现100%的代码覆盖率,而神经元覆盖率则不到10%。
接下来,本文展示如何将具有相似功能的多个DL系统(例如Google,Tesla和GM的无人驾驶汽车)用作cross-referencing oracles,以识别产生错误的极端情况而无需手动检查。例如,如果一辆自动驾驶汽车决定左转而其他汽车右转以求相同的输入,则其中一方可能是不正确的。过去,这种差分测试技术已成功应用于各种传统软件中,无需手动说明即可检测逻辑错误。本文演示了如何将差分测试应用于DL系统。
最后,本文演示了如何将生成最大化DL系统神经元覆盖范围并同时暴露尽可能多的差异行为(即,多个相似DL系统之间的差异)的测试输入的问题作为联合优化问题解决。与传统程序不同,由DL系统使用的最流行的深度神经网络(DNN)近似的功能是可区分的。因此,在白盒访问相应模型的情况下,可以准确计算它们相对于输入的梯度。本文展示了如何使用这些梯度来有效地解决大型现实世界DL系统的上述联合优化问题。
本文设计,实施和评估DeepXplore,这是用于大型DL系统的第一个有效白盒测试框架。除了最大程度地提高DL系统之间的神经元覆盖范围和行为差异之外,DeepXplore还支持用户添加自定义约束,以模拟不同类型的实际输入(例如,不同类型的照明和图像/视频的遮挡)。本文证明了DeepXplore在15种最先进的DL模型中有效地发现了数千种独特的不正确的极端情况行为(例如,无人驾驶汽车撞到护栏),这些模型使用包括Udacity自动驾驶汽车挑战赛、ImageNet和MNIST的图像数据,Drebin的Android恶意软件数据以及Contagio / VirusTotal的PDF恶意软件数据在内的五个真实数据集进行了训练。对于所有经过测试的DL模型,平均而言,DeepXplore能在一台商用笔记本电脑上,在一秒钟内生成一个测试输入从而表现出错误行为。与相同数量的随机选择输入和对抗性输入相比,DeepXplore生成的输入分别平均提高了34.4%和33.2%的神经元覆盖率。本文进一步表明,由DeepXplore生成的测试输入可用于重新训练相应的DL模型,以提高分类准确性以及识别潜在污染的训练数据。与对相同数量的随机或对抗输入进行再训练相比,通过对DeepXplore生成的输入进行再训练一个DL模型,可以将分类精度提高多达3%。
本文主要贡献是:
- 本工作将神经元覆盖率作为DL系统的第一个白盒测试度量标准,可以估计一组测试输入所探索的DL逻辑数量。
- 本工作证明,在最大化神经元覆盖范围的同时,在相似的DL系统之间发现大量行为差异的问题可以表述为联合优化问题。本文提出了一种基于梯度的算法来有效解决该问题。
- 本工作将所有这些技术作为DeepXplore的一部分实施,DeepXplore是第一个白盒DL测试框架,它使用五个流行的数据集进行训练,在15个最新的DL模型中暴露了上千个错误的极端情况(例如,自动驾驶汽车撞到护栏,如图1所示),训练了总共132057个神经元,这些数据集包含大约162GB的数据。
- 本工作证明,DeepXplore生成的测试还可用于重新训练相应的DL系统,从而将分类准确性提高多达3%。

2 BackGround
2.1 DL Systems
本文将DL系统定义为包括至少一个深度神经网络(DNN)组件的任何软件系统。
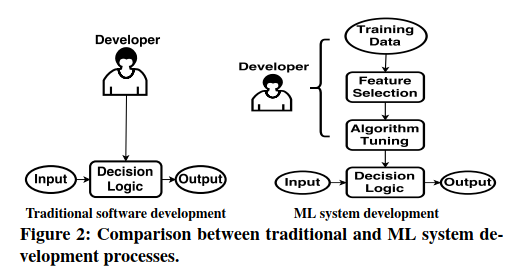
请注意,某些DL系统可能仅由DNN组成(例如,无需任何手动规则即可预测转向角的自动驾驶汽车DNN),而另一些系统可能具有一些DNN组件与其他传统软件组件进行交互以产生最终输出。DL系统的DNN组件的开发过程从根本上不同于传统的软件开发。与开发人员直接指定系统逻辑的传统软件不同,DNN组件从数据中自动学习其规则。 DNN组件的开发人员可以通过修改训练数据,特征和模型的架构细节(例如,层数)来间接影响DNN学习的规则,如图2所示。
由于DNN的规则甚至对于其开发人员来说都是未知的,因此在安全关键的环境中,测试和修复DNN的错误行为至关重要。本文主要侧重于自动查找触发DL系统中错误行为的输入,并提供有关如何通过增加或过滤7.3章节中的训练数据来使用这些输入来修正错误行为的初步证据。
2.2 DNN Architecture
DNN受具有数百万个相互连接的神经元的人脑启发。它们以惊人的能力自动识别并从原始输入中提取相关的高级特征而闻名,除了带标签的训练数据外,无需任何人工指导。近年来,由于大型数据集,专用硬件和有效的训练算法的可用性不断提高,DNN在许多应用领域中都超过了人类的性能。DNN由多层组成,每个层包含多个神经元,如图3所示。神经元是DNN内部的一个单独的计算单元,在其输入上施加激活函数并将结果传递给其他连接的神经元。常见的激活函数包括sigmoid,hyperbolic tangent(双曲正切)或ReLU(修正线性单元)。DNN通常至少具有三层(通常是更多层):一个输入,一个输出以及一个或多个隐藏层。一层中的每个神经元都直接连接到下一层中的神经元。每一层中神经元的数量以及它们之间的联系在DNN中差异很大。总的来说,DNN可以在数学上定义为一个多输入,多输出的参数函数$F$ ,由代表不同神经元的许多参数子函数组成。
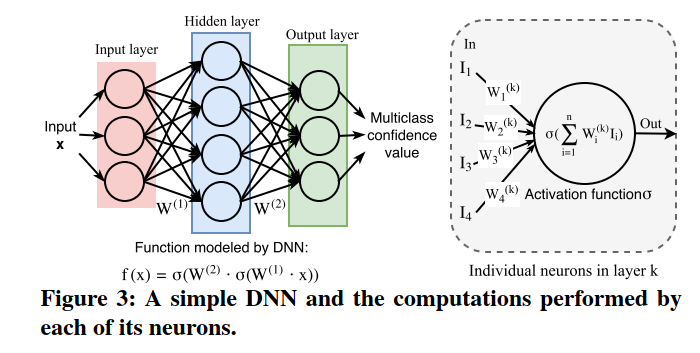
DNN中神经元之间的每个连接都绑定到一个权重参数$weight$,该参数表征了神经元之间的连接强度。对于监督学习,通过在训练数据上最小化cost function(loss function),在训练过程中学习连接的权重。可以使用不同的训练算法来训练DNN,但是迄今为止,使用反向传播的梯度下降是DNN最受欢迎的训练算法。
网络的每一层都将其输入中包含的信息转换为数据的更高层表示。例如,考虑图4b中所示的预训练网络,该网络将图像分为两类:人脸和汽车。前几个隐藏层将原始像素值转换为低级纹理特征(如边缘或颜色),并将其提供给更深层。最后几层依次提取并组合有意义的高级抽象,例如鼻子,眼睛,车轮和前灯,以做出分类决策。
2.3 Limitations of Existing DNN Testing
开销极大的标记工作 现有的DNN测试技术需要花费巨大的人力才能为目标任务提供正确的标签/动作(例如,自动驾驶汽车,图像分类和恶意软件检测)。对于复杂的高维真实世界输入,人类,甚至是领域专家,通常也难以有效地为大型数据集正确执行任务。例如,考虑一个旨在识别潜在恶意可执行文件的DNN。即使是安全专家,也很难在不执行可执行文件的情况下确定其是恶意的还是良性的。但是,在沙箱内执行和监视恶意软件会导致大量的性能开销,因此人工标记明显难以扩展到大量输入。
低测试覆盖率 现有的DNN测试方案均未尝试涵盖DNN的不同规则。因此,测试输入通常无法发现DNN的不同错误行为。
例如,对DNN的测试经常通过简单地将整个数据集分为两个随机部分(一个用于训练,另一个用于测试)来进行。在这种情况下,测试集可能只行使DNN学习的所有规则的一小部分。涉及对DNN进行对抗式回避攻击的最新结果表明,存在一些极端的情况,其中基于DNN的图像分类器(在随机选取的测试集上具有最先进的性能)仍然错误地对通过在测试图片中添加难以察觉的扰动而生成的合成图像进行分类。除此之外,对抗性输入类似于随机测试输入,也仅覆盖了DNN学习的规则的一小部分,因为它们并非旨在最大化覆盖范围。此外,它们本质上也仅限于测试输入周围的细微不明显的扰动,因为较大的扰动会在视觉上改变输入,因此需要人工检查以确保DNN决策的正确性。
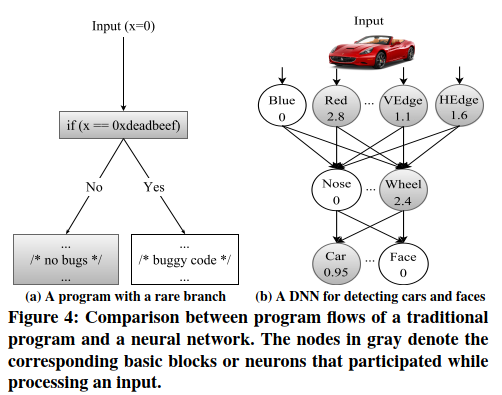
低覆盖率DNN测试的问题 为了更好地理解DNN学习的规则的测试覆盖率低的问题,本文提供一个类似于测试传统软件问题的类比。图4显示了传统程序和DNN如何处理输入和产生输出的并排比较。具体来说,该图显示了传统软件与DNN的相似之处:在软件程序中,每个语句执行特定的操作以将前一个语句的输出转换为后一个语句的输入,而在DNN中,每个神经元将前一个神经元的输出转换为后一个神经元的输入。当然,与传统软件不同,DNN没有明确的分支,但是随着神经元输出值的降低,神经元对下游神经元的影响会降低。较低的输出值表示影响较小,反之亦然。当神经元的输出值变为零时,该神经元对下游神经元没有任何影响。
如图4a所示,测试传统软件时覆盖率低的问题是显而易见的。在这种情况下,除非测试输入为0xdeadbeef,否则永远不会看到buggy行为。随机选择到某个特定值的概率很小。同样,低覆盖率的测试输入也将使DNN的不同行为无法探索。例如,考虑一个简化的神经网络,如图4b所示,它将图像作为输入并将其分类为两个不同的类别:汽车和脸。每个神经元中的文本(表示为节点)表示该神经元检测到的对象或属性,每个神经元中的数字是该神经元输出的实际值。数字表示神经元对其输出的置信度。请注意,对于不太可能的神经元组合,随机选择的输入极不可能设置高输出值。因此,即使执行大量随机测试后,许多不正确的DNN行为仍将无法发现。例如,如果图像导致标有“ Nose”和“ Red”的神经元产生高输出值,而DNN将输入图像错误地分类为汽车,这种行为在常规测试期间不会出现,因为图像包含一个红鼻子(例如一个小丑的照片)的概率很小。
3 OverView
本节中提供DeepXplore的概述,DeepXplore是本工作的白盒框架,用于系统地测试DNN的错误极端情况行为。DeepXplore的主要组件如图5所示。DeepXplore将未标记的测试输入作为种子,并生成覆盖大量神经元的新测试(即,将它们激活到一个高于可定制阈值的值),并导致被测DNN的行为有所不同。具体来说,DeepXplore解决了一个联合优化问题,即最大化差异行为和神经元覆盖率。请注意,这两个目标对于彻底测试DNN和发现各种错误的极端情况行为都是至关重要的。仅仅高的神经元覆盖可能不会引发许多错误的行为,而仅仅最大化不同的行为可能只是识别出相同根本原因的不同表现。
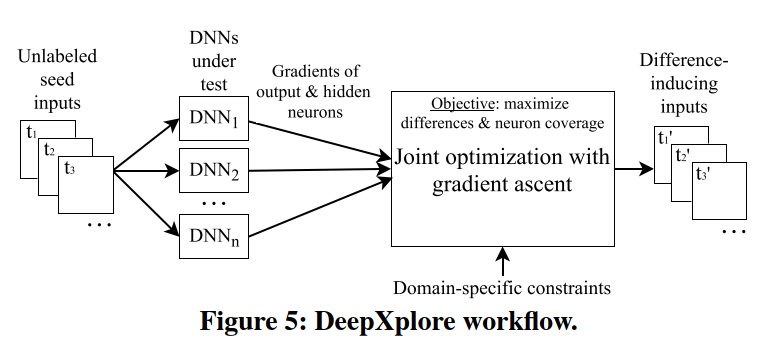
作为联合优化过程的一部分,DeepXplore还支持强制自定义特定于域的约束。例如,图像像素的值必须在0到255之间。DeepXplore的用户可以指定此类特定于域的约束,以确保生成的测试输入有效且逼真。
本工作设计了一种算法,可以使用梯度上升有效地解决上述联合优化问题。首先,以输入值为变量,权重参数为常数,计算输出层和隐藏层中神经元输出的梯度。对于大多数DNN,可以有效地计算这样的梯度。请注意,DeepXplore设计为可在预训练的DNN上运行。由于本文的白盒方法可以访问预先训练的DNN的权重和中间神经元值,因此梯度计算非常有效。接下来,迭代执行梯度上升以修改测试输入,以使上述联合优化问题的目标函数最大化。本质上,从种子输入开始执行由梯度指导的局部搜索,然后找到可以最大化所需目标的新输入。请注意,在较高的层次上,本工作的梯度计算与DNN训练期间执行的反向传播相似,但主要区别在于,与本工作的算法不同,反向传播将输入值视为常量,并将权重参数视为变量。
一个有效的例子。以图6为例,展示DeepXplore如何生成测试输入。假设有两个要测试的DNN,它们都执行相似的任务,即将图像分类为汽车或人脸,但它们分别使用不同的数据集和参数进行训练。因此,DNN将学习相似但略有不同的分类规则。假设我们有一个种子测试输入,即红色汽车的图像,这两个DNN都将其识别为汽车,如图6a所示。
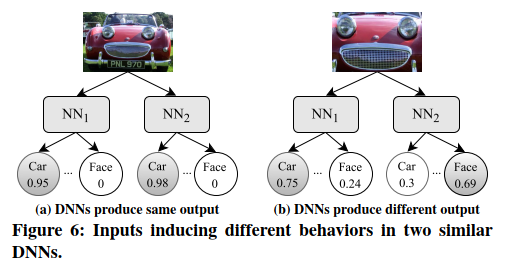
DeepXplore尝试通过修改输入(即红色汽车的图像)来最大化发现差异行为的机会,以最大程度地将其被一个DNN分类为汽车的概率,同时将另一个DNN的相应概率最小化。 DeepXplore还尝试通过激活隐藏层中的非活跃神经元(即,使神经元的输出值大于阈值)来覆盖尽可能多的神经元。本工作还添加了特定于域的约束条件,以确保修改后的输入仍然代表真实世界的图像。联合优化算法将迭代执行梯度上升,以找到满足上述所有目标的修改后的输入。 DeepXplore最终会生成一组测试输入,其中DNN的输出有所不同,例如,如图6b所示。
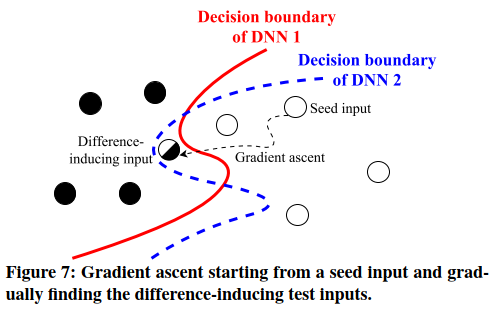
图7说明了使用梯度上升技术的基本概念。从种子输入开始,DeepXplore在应该执行相同任务的两个相似DNN的输入空间中,通过梯度执行引导搜索,从而最终发现位于这些DNN的决策边界之间的测试输入。两种DNN将对这些测试输入进行不同的分类。请注意,虽然渐变会为实现目标提供大致的方向(例如,找到引起差异的输入),但并不能保证最快的收敛速度。因此,如图7所示,梯度上升过程通常不会沿着直线路径到达目标。
4 Methodology
在本节中,提供了有关算法的详细技术说明。首先,定义和解释DNN的神经元覆盖率和梯度的概念。接下来,描述如何将测试问题表述为联合优化问题。最后,提供了基于梯度的算法来解决联合优化问题。
4.1 Definitions
神经元覆盖(Neuron Coverage) 本工作将一组测试输入的神经元覆盖率定义为所有测试输入的唯一激活神经元数量与DNN中神经元总数的比率。如果神经元的输出高于阈值(例如0),我们认为该神经元将被激活。
更正式地说,假设DNN的所有神经元都由集合$N = {n_1,n_2,\cdots}$表示,所有测试输入都由集合$T = {\boldsymbol{x_1},\boldsymbol{x_2},\cdots}$表示, $out(n,\boldsymbol{x})$是针对给定的测试输入$\boldsymbol{x}$返回DNN中神经元$n$的输出值的函数。请注意,粗体$\boldsymbol{x}$表示$\boldsymbol{x}$是向量。令t代表考虑要激活的神经元的阈值。在这种情况下,神经元覆盖率可以定义如下。
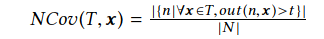
为了演示在实践中如何计算神经元覆盖率,考虑图4b中所示的DNN。图4b中所示的红色汽车输入图片的神经元覆盖率(阈值为0)将为$5/8 = 0.625$。
梯度。DNN神经元输出相对于输入的梯度或前向导数(forward derivative)在深度学习文献中是众所周知的。它们已被广泛用于制作对抗示例和可视化/理解DNN。
令$\boldsymbol\theta$和$\boldsymbol{x}$分别代表DNN的参数和测试输入。由神经元执行的参数函数可以表示为$y=f(\boldsymbol\theta,\boldsymbol{x})$,其中$f$是将$\boldsymbol\theta$和$\boldsymbol{x}$作为输入和$y$作为输出的函数。请注意,$y$可以是DNN中定义的任何神经元的输出(例如,来自输出层或中间层的神经元)。$f(\boldsymbol\theta,\boldsymbol{x})$相对于输入$\boldsymbol{x}$的梯度可以定义为:
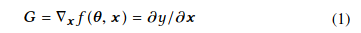
$f$内部的计算本质上是一系列堆叠函数,这些函数计算来自上一层的输入并将输出转发到下一层。因此,可以通过利用微积分中的链式规则,即通过计算从输出$y$的神经元层开始直到到达将用作$\boldsymbol{x}$输入的输入层的分层导数,来计算$G$。注意,梯度$G$的维度与输入$\boldsymbol{x}$的维度相同。
4.2 DeepXplore algorithm
与传统软件相比,DNN的测试输入生成过程的主要优势在于,测试生成过程一旦定义为优化问题,就可以使用梯度上升有效地解决。本节将描述公式的细节并找到优化问题的解决方案。请注意,与传统软件不同,DNN的目标函数的梯度可以轻松计算,因此可以为DNN高效地找到优化问题的解决方案。
如第3节中所述,测试生成过程的目的是在保留用户提供的特定领域约束的同时,最大化观察到的差异行为和神经元覆盖范围。算法1显示了通过解决此联合优化问题来生成测试输入的算法。下面,本文正式定义联合优化问题的目标,并详细说明解决该问题的算法。
最大化差异行为 优化问题的第一个目标是生成可在被测DNN中引起不同行为的测试输入,即不同的DNN将相同的输入分类为不同的类别。假设我们有n个DNN $F_{k\in 1..n}:\boldsymbol{x}\rightarrow\boldsymbol{y}$,其中$F_k$是由第k个神经网络建模的函数。 x代表输入,y代表输出类别概率向量。给定任意x作为种子,其中x被所有DNN都归为同一类,本工作的目标是修改x,以使修改的输入x’被n个DNN中的至少一个归为不同类。

令$F_k(\boldsymbol{x})[c]$为$F_k$预测x为c的类概率。随机选择一个神经网络$F_j$(算法1 Line 6)并最大化以下目标函数:
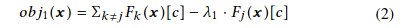
其中$\lambda_1$是一个参数,用于平衡与之前保持相同的类输出的DNN $F_{k\neq j}$和产生不同类输出的DNN $F_j$之间的目标项。由于$F_{k\in 1..n}$全部是可微的,可以通过基于计算出的梯度$\frac{\partial obj_1(\boldsymbol{x})}{\partial \boldsymbol{x}}$迭代更改x来轻松地使用梯度上升最大化方程2:(算法1 Line 8-14和Procedure COMPUTE_OBJ1)。
最大化神经元覆盖率 第二个目标是生成使神经元覆盖范围最大化的输入。本工作通过迭代地选择不活跃的神经元并修改输入以使该神经元的输出超过神经元激活阈值来实现此目标。假设我们想要最大化神经元n的输出,即我们想要最大化$obj_2(\boldsymbol{x})=f_n(\boldsymbol{x})$使得$f_n(\boldsymbol{x})>t$,其中$t$是神经元激活阈值,$f_n(\boldsymbol{x})$是由神经元$n$建模的函数,该函数将$\boldsymbol{x}$(DNN的原始输入)作为输入并产生神经元$n$的输出(如公式1所定义)。我们可以再次利用梯度上升机制,因为$f_n(\boldsymbol{x})$是一个可微函数,其梯度为$\frac{\partial f_n(\boldsymbol{x})}{\partial \boldsymbol{x}}$。
注意,可以同时联合地最大化多个神经元,但是为了清楚起见,本文选择一次激活一个神经元(算法1 Line8-14 和{procedure COMPUTE_OBJ2)。
联合优化 本工作联合最大化上述的$obj_1$和$f_n$,并最大化以下函数:
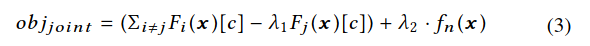
其中$\lambda_2$是用于平衡联合优化过程的两个目标的参数,$n$是在每次迭代中随机选择的不活跃神经元(算法1第33行)。由于$obj_{joint}$的所有项都是可微的,因此通过修改$\boldsymbol{x}$(算法1第14行),使用梯度上升来联合最大化它们。
特定于域的约束 优化过程的一个重要方面是,生成的测试输入需要满足一些特定于域的约束才能切合实际。特别是,要确保在第i次梯度上升过程中应用于$\boldsymbol{x}_i$的更改满足所有i的所有特定于域的约束。例如,对于生成的测试图像$\boldsymbol{x}$,像素值必须在特定范围内(例如0到255)。
尽管可以使用类似于支持向量机中使用的拉格朗日乘子将某些约束有效地嵌入到联合优化过程中,本工作发现,优化算法无法轻松处理其中的大多数约束。因此,本文设计了一种简单的基于规则的方法,以确保生成的测试满足特定于自定义域的约束。由于种子输入$\boldsymbol{x}_{seed} = \boldsymbol{x}_0$始终满足定义的约束,因此本文的技术必须确保在梯度上升的第i次(i> 0)迭代之后,$\boldsymbol{x}_i$仍满足约束。本文的算法通过修改梯度grad(算法1中的第13行)确保$\boldsymbol{x}_{i+1}=\boldsymbol{x}_i+s\cdot grad$仍满足约束条件(s是梯度上升中的步长),从而确保了此属性。
对于离散特征,本文将梯度四舍五入为整数。对于处理视觉输入(例如图像)的DNN,本文添加了不同的空间限制,以便仅修改部分输入图像。
算法1中的超参数 总而言之,有四个主要的超参数控制着DeepXplore的不同方面,
- $\lambda_1$平衡最小化一个DNN对某个标签的预测与最大化其余DNN对相同标签的预测之间的目标。较大的$\lambda_1$在降低特定DNN的预测值/置信度上具有较高的优先级,而较小的$\lambda_1$在保持其他DNN的预测上具有更大的权重。
- $\lambda_2$平衡发现差异行为和神经元覆盖。较大的$\lambda_2$将更多的精力集中在覆盖不同的神经元上,而较小的$\lambda_2$将产生更多的差异诱导(difference-inducing)测试输入。
- $s$控制迭代梯度上升过程中使用的步长。较大的$s$可能导致围绕局部最优解的振荡,而较小的$s$可能需要更多次迭代才能达到目标。
- $t$是确定每个神经元是否被激活的阈值。随着t的增加,寻找激活神经元的输入变得越来越困难。
5 Implementation
本工作使用TensorFlow 1.0.1和Keras 2.0.3DL框架实现DeepXplore。本文的实现包含大约7086行Python代码。本文的代码基于TensorFlow / Keras构建,但是不需要对这些框架进行任何修改。本文在联合优化过程中利用TensorFlow高效地实现梯度计算。 TensorFlow还支持创建子DNN,方法是将任意神经元的输出标记为子DNN的输出,同时保持输入与原始DNN的输入相同。本文使用此功能来拦截和记录DNN中间层中神经元的输出,并计算相对于DNN输入的相应梯度。本文所有的实验都在运行Ubuntu 16.04的Linux笔记本电脑上运行(一个Intel i7-6700HQ 2.60GHz处理器,具有4核,16GB内存和NVIDIA GTX 1070 GPU)。
6 Experimental Setup
6.1 Test datasets and DNNs
本工作采用五个流行的公共数据集,它们具有不同类型的数据(MNIST,ImageNet,Driving,Contagio/VirusTotal和Drebin),本工作针对每个数据集在三个DNN上评估DeepXplore(即总共15个DNN)。表1中提供了五个数据集和相应DNN的摘要。所有评估过的DNN都是经过预先训练的(即,使用以前研究人员报告公开的权重),或者使用公开的real-world架构来进行训练,以实现对于相应数据集的可比较性能最新模型。对于每个数据集,本文使用DeepXplore来测试具有不同架构的三个DNN,如表1所示。
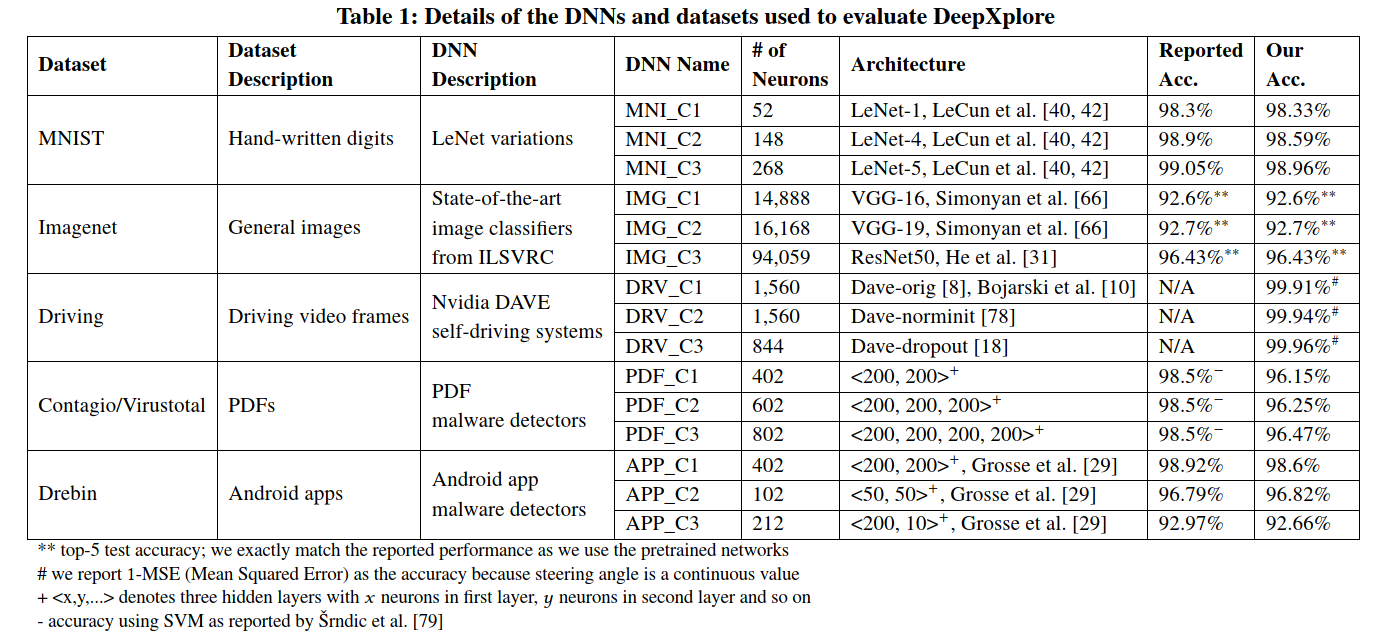
MNIST 是一个大型手写数字数据集,包含28x28像素图像,类别标签为0到9。该数据集包括60000个训练样本和10000个测试样本。本工作遵循Lecun等人并基于LeNet家族构建三个不同的神经网络,即LeNet-1,LeNet-4和LeNet-5。
ImageNet 是一个大型图像数据集,其中包含10000000幅手动注释的图像,这些图像被众包并手动标记。本文测试了三个著名的预训练DNN:VGG-16,VGG-19和ResNet50。这三个DNN在ILSVRC竞赛中均取得了有竞争力的表现。
Driving 是Udacity自动驾驶汽车挑战赛数据集,其中包含安装在驾驶车辆挡风玻璃后方的摄像头捕获的图像以及人类驾驶员为每个图像应用的同时方向盘角度。该数据集包含101396个训练和5614个测试样本。然后,本文基于Nvidia的DAVE-2自动驾驶汽车架构使用了三个DNN,它们的配置略有不同,分别称为DAVE-orig,DAVE-norminit和DAVE-dropout。具体来说,DAVE-orig完全复制了Nvidia论文中的原始架构。DAVE-norminit删除了第一批标准化层,并标准化了随机初始化的网络权重。 DAVE-dropout通过减少卷积层和完全连接层的数量来简化DAVE-orig。DAVE-dropout还在最后三个完全连接的层之间添加了两个dropout层。本文使用上面提到的Udacity自动驾驶汽车挑战数据集训练了所有三种实现方式。
Contagio/VirusTotal 是一个数据集,其中包含不同的良性和恶意PDF文档。本文使用来自Contagio数据库的5000个良性和12205个恶意PDF文档作为训练集,然后使用VirusTotal收集的5000个恶意PDF和从Google抓取的5000个良性PDF作为测试集。据本工作团队所知,还没有公开可用的基于DNN的PDF恶意软件检测系统。因此,我们使用PDFrate中的135种静态功能定义和训练了三种不同的DNN,这是一种用于检测PDF恶意软件的在线服务。具体来说,本工作构建了一个神经网络,该神经网络具有一个输入层,一个softmax输出层以及具有200个神经元的N个全连接的隐藏层,其中三个测试的DNN的N范围从2到4。本文所有的模型都实现了与以前的工作在相同数据集上使用SVM模型报告的模型相似的性能。
Drebin 是一个具有129013个Android应用程序的数据集,其中123453个为良性,5560个为恶意。共有545333个二进制函数,分为八类,包括从manifest文件捕获的功能(例如,请求的权限和意图)和反汇编的代码(例如,受限制的API调用和网络地址)。本文采用Grosse等人构建的36个DNN中的3个的架构。由于无法获得DNN的权重,因此本文将使用66%从数据集中随机选择的Android应用程序训练这三个DNN,并将其余的作为测试集。
6.2 Domain-specific constraints
如前所述,为了在实践中有用,需要通过应用特定于域的约束来确保生成的测试是有效且现实的。例如,生成的图像应该可以由相机物理地制作。同样,生成的PDF需要遵循PDF规范,以确保PDF查看器可以打开测试文件。下面描述了本文中使用的两种主要类型的特定于域的约束(即图像和文件约束)。
图像约束(MNIST,ImageNet和Driving) DeepXplore使用三种不同类型的约束来模拟图像的不同环境条件:
- 模拟不同强度的光线的照明效果;
- 被单个小矩形遮挡以模拟攻击者可能遮挡摄像头的某些部分;
- 被多个黑色小矩形遮挡,以模拟灰尘对相机镜头的影响。
第一个约束限制了图像修改,因此DeepXplore只能使图像变暗或变亮,而不会更改其内容。具体来说,修改只能将所有像素值增加或减少相同的量(例如,算法1第14行中的1*步长)——决定增加还是减少取决于均值(G)的值,其中G表示梯度,在每次梯度上升迭代时计算。请注意,mean(G)仅表示多维数组G中所有条目的均值。图8的第一行和第二行显示了DeepXplore在这些约束条件下生成的差异诱导输入的一些示例。
第二个约束模拟单个小矩形R($m\times n$像素)可能偶然或有意遮盖的相机镜头的效果。具体来说,本工作仅将$G_{i:i+m,j:j+n}$应用于原始图像(I),其中$I_{i:i+m,j:j+n}$是R的位置。请注意,DeepXplore可以给i和j自由选择任意值从而将矩形R放在图像内的任意位置。图8的第三和第四行显示了使用这种遮挡约束运行时生成的DeepXplore示例。

第三个约束条件限制了修改,因此在每次梯度上升迭代期间,DeepXplore仅从G的左上角坐标(i,j)的位置选择一个$m\times m$大小的小块$G_{i:i+m,j:j+m}$。如果此补丁的平均值$mean(G_{i:i+m,j:j+m})$大于0,则设置$G_{i:i+m,j:j+m}=0$,即,仅允许像素值减少。与上述第二个约束不同,此处DeepXplore将选择多个位置(即多个(i,j)对),以将模拟灰尘的黑色矩形放置在相机镜头上。图8的第五行和第六行显示了一些具有这些约束的示例。
其他限制(Drebin和Contagio / VirusTotal) 对于Drebin数据集,DeepXplore强制执行约束,该约束仅允许修改与Android清单文件相关的功能,从而确保应用程序代码不受影响。此外,DeepXplore仅允许从清单文件中添加功能(从0更改为1),而不允许删除功能(从1更改为0),以确保不会由于权限不足而更改应用程序功能。因此,在计算梯度后,DeepXplore仅修改其对应梯度大于零的清单特征。
对于Contagio / VirusTotal数据集,DeepXplore遵循Šrndic等人描述的对每个功能的限制。
7 Results
Summary DeepXplore在所有经过测试的DNN中发现了数千种错误行为。表2总结了DeepXplore为每个测试的DNN发现错误行为的次数,同时使用了来自相应测试集的2,000个随机选择的种子输入。请注意,由于测试集每个类别的样本数量相似,因此随机选择的2,000个样本也遵循该分布。如表2所示,根据经验选择这些实验的超参数值,以使找到差异输入的速率以及由这些输入实现的神经元覆盖率最大化。

对于图8中所示的实验结果,应用了第6.2节中所述的三个特定于域的约束(照明效果,单个矩形的遮挡和多个矩形的遮挡)。对于涉及视觉相关任务的所有其他实验,仅将照明效果用作特定领域的约束。对于所有与恶意软件相关的实验,本文应用第6.2节中所述的所有相关领域特定约束。除非另有说明,否则本文在所有实验中均使用表2中列出的超参数值。
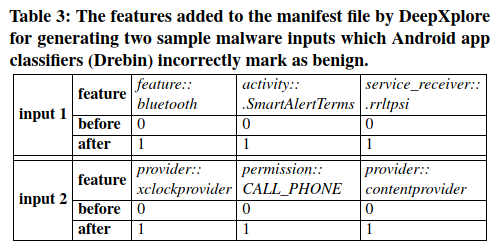
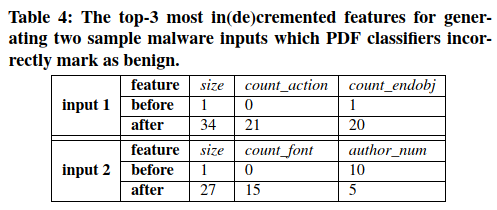
图8显示了DeepXplore为MNIST,ImageNet和Driving数据集(具有不同的特定于域的约束)生成的一些引起差异的输入,以及相应的错误行为。表3(Drebin)和表4(Contagio/VirusTotal)显示了DeepXplore生成的两个样本差异诱导输入,这些输入在被测DNN中导致错误行为。本文重点介绍了种子输入功能和DeepXplore修改的功能之间的区别。请注意,由于篇幅所限,本文仅列出了前三个修改后的功能。
7.1 Benefits of neuron coverage
本小节中将评估神经元覆盖率(本文提出的新指标)在衡量DNN测试的全面性方面的效果。最近的研究表明,DNN中的每个神经元都倾向于独立地提取输入的特定特征,而不是与其他神经元协作以进行特征提取。本质上,每个神经元倾向于学习与其他神经元不同的一组规则。这一发现直观地解释了为什么神经元覆盖率是DNN测试全面性的良好指标。为了从经验上确认此观察,本文执行了以下两个不同的实验。
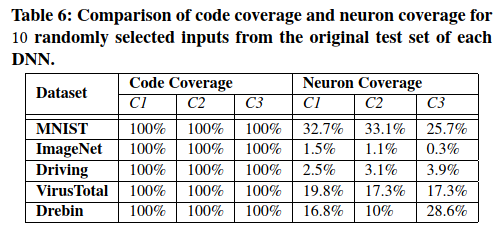
首先,本文证明在测量DNN测试输入的全面性方面,神经元覆盖率比代码覆盖率好得多。更具体地说,本文发现,对于所有DNN,少量的测试输入就可以实现100%的代码覆盖率,而神经元覆盖率实际上均小于34%。
其次,本文评估来自不同类别的测试输入的神经元激活。本文的结果表明,与来自同一类别的输入相比,来自不同类别的输入倾向于激活更多独特的神经元。两项发现均证实,神经元覆盖率可以很好地估计输入所行使的DNN规则的数量和类型。
Neuron coverage vs. code coverage 通过在第6.1节中所述的十个随机选择的测试样本上评估的测试DNN,本文比较了相同数量的输入所实现的代码覆盖率和神经元覆盖率。本文根据训练和测试过程中使用的Python代码的行覆盖率来衡量DNN的代码覆盖率。本文将神经元覆盖率阈值$t$设置为0.75,即仅当至少一个输入的神经元输出大于0.75时,才认为该神经元被覆盖。
请注意,对于中间层输出产生的值与最终层输出范围不同的DNN,本文通过计算$out-min(out)/(max(out)-min(out))$,其中$out$是表示给定层所有神经元输出的向量。
如表6所示,结果清楚地表明,在测量DNN测试的全面性方面,神经元覆盖率比代码覆盖率好得多。即使10个随机选择的输入也会导致所有DNN的代码覆盖率达到100%,而对任意DNN来说,神经元覆盖率永远不会超过34%。此外,基于已测试的DNN和测试输入,神经元覆盖率将发生显着变化。例如,完整的MNIST测试集(即10,000个测试样本)的神经元覆盖率分别仅为C1,C2和C3分别达到57.7%,76.4%和83.6%。相比之下,完整的Contagio/Virustotal测试集的神经元覆盖率达到100%。
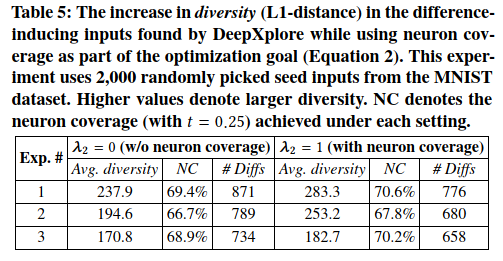
Effect of neuron coverage on the difference-inducing inputs found by DeepXplore 将最大神经元覆盖率作为联合优化过程中的目标之一,其主要目标是生成各种差异诱导输入。本实验中评估了神经元覆盖范围在实现此目标方面的有效性。
本文从MNIST测试数据集中随机抽取2,000个种子输入,并通过分别在等式2中将$\lambda_2$设置为1和0,使用DeepXplore生成具有和不具有神经元覆盖的差异诱导输入。本文根据从相同种子和原始种子生成的所有差异诱导输入之间的平均L1距离来衡量所生成差异诱导输入的多样性。 L1距离计算生成的图像和原始图像之间每个像素值的绝对差(absolute difference)之和。表5展示了三个此类实验的结果。结果清楚地表明,神经元覆盖率有助于增加生成的输入的多样性。
请注意,即使通过设置$\lambda_2 =1$而不是$\lambda_2=0$来实现的神经元覆盖率增加的绝对值看起来很小(例如1-2个百分点),它对增加所产生差异诱导图像的多样性也有重大影响,如表5所示。这些结果表明,与代码覆盖率相似,增加神经元覆盖率以获得更高的值变得越来越困难,但是即使神经元覆盖率很小的增加也可以显著改善测试多样性。同样,以$\lambda_2 =1$生成的差异诱导输入的数量少于$\lambda_2 =0$的数量,因为设置$\lambda_2 =1$会使DeepXplore专注于发现差异,而不是简单地增加具有相同根本原因(root cause)的差异数量。一般而言,仅差异诱导输入的数量无法衡量与视觉相关任务的生成的测试的质量,因为它可以对一个已有的差异诱导图像作微小的变化从而生成大量的具有相同根本原因的差异诱导图像。
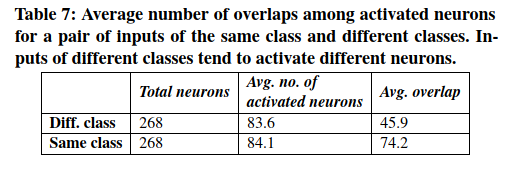
Activation of neurons for different classes of inputs 本实验中测量了在相同和不同类别的MNIST输入对上运行的LeNet-5 DNN中共有的活跃神经元的数量。特别地,本实验随机选择200个输入对,其中100对具有相同的标签(例如,标记为8),而100对具有不同的标签(例如,标记为8和4)。然后,计算这些输入对的常见(重叠)活动神经元的数量。表7显示了结果,这证实了本文的假设,即来自相同类别的输入比来自不同类别的输入具有更多的相同激活神经元。由于倾向于通过匹配不同的DNN规则来检测来自不同类别的输入,因此本实验的结果还证实,神经元覆盖率可以有效地估计DNN测试期间激活的不同规则的数量。
7.2 Performance
本文使用两个指标来评估DeepXplore的性能:生成的测试数据的神经元覆盖率和生成差异诱导的输入的执行时间。
神经元覆盖率 本实验中比较了通过三种不同方法生成的相同数量的测试获得的神经元覆盖率:
- DeepXplore
- 对抗测试
从原始测试集中随机选择
结果显示于表8和图9。可以从结果中得出两个关键结论。首先,如图9所示,DeepXplore平均比随机测试和对抗测试覆盖的神经元多34.4%和33.2%,其次,神经元覆盖率阈值$t$决定了神经元是否被激活, 极大地影响了神经元的覆盖率。随着阈值$t$的增加,这三种方法都覆盖了较少的神经元。这是直观的,因为较高的t值使得使用简单的修改来激活神经元变得越来越困难。
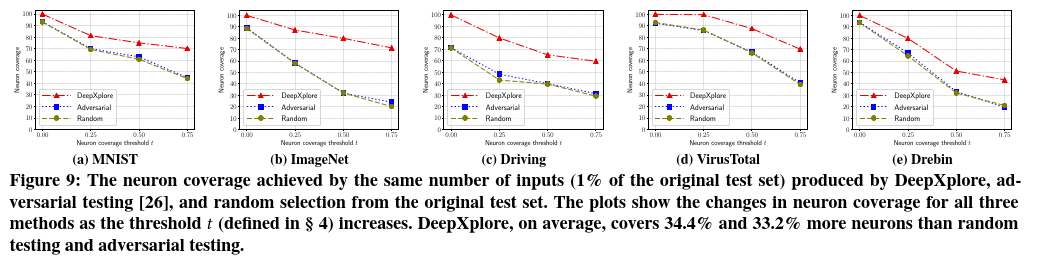
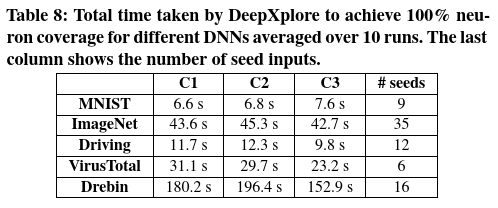
执行时间和种子输入数量 本实验中测量DeepXplore的执行时间,以针对所有测试的DNN生成具有100%神经元覆盖率的差异诱导输入。能注意到,MNIST,ImageNet和Driving上DNN的全连接层中的某些神经元很难激活,因此,本实验仅考虑除全连接层之外的层上的神经元覆盖率。表8显示了结果,表明DeepXplore在寻找差异诱导的输入以及增加神经元覆盖率方面非常有效。
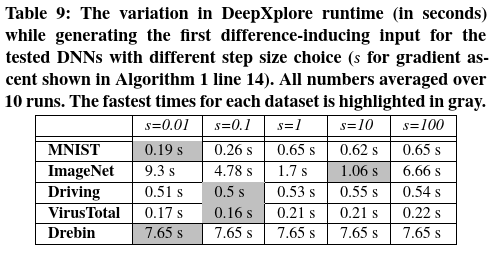
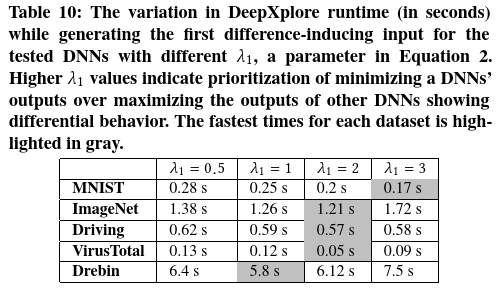
超参数的不同选择 本文进一步评估了DeepXplore的不同超参数(如4.2中所述的$s$,$\lambda_1$,$\lambda_2$和$t$)的选择如何影响DeepXplore的性能。如前所述,改变神经元激活阈值t的影响如图9所示。表9、10和11显示了DeepXplore运行时随$s$,$\lambda_1$和$\lambda_2$的变化而变化的情况。结果表明,$s$和$\lambda_1$的最佳值在不同DNN和数据集中有所不同,而$\lambda_2= 0.5$倾向于对所有数据集都是最佳的。
本实验使用DeepXplore找到第一个差异诱导的输入 花费的时间,作为比较表9,表10和表11中不同选择的超参数的度量。本工作选择此度量标准是因为实验中发现,找到给定种子的第一个差异诱导输入往往比增加差异诱导输入的数量困难得多。
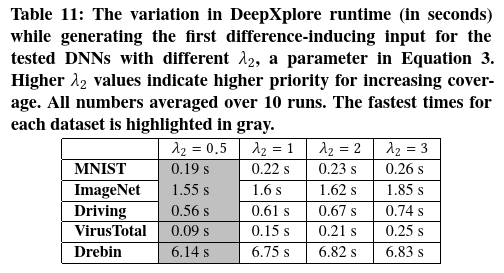
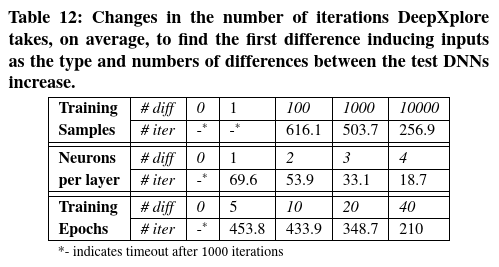
使用DeepXplore测试非常相似的模型 请注意,尽管DeepXplore的梯度指导测试生成过程在实践中效果很好,但在某些情况下,尤其是对于决策边界非常相似的DNN,可能无法在合理的时间内找到任何引起差异的输入。为了估计必须具备多少相似性的DNN,会使DeepXplore在实践中失败,本工作控制两个DNN之间的三种类型的差异,并测量在每种情况下生成第一个引起差异的输入所需的迭代变化。
本实验使用MNIST训练集(60000个样本)和LeNet-1训练了10个epoch作为对照组。本实验分别更改
- 训练样本数
- 每个卷积层的filter数
- 训练epoch数以创建LeNet-1的变体
表12总结了DeepXplore所需的平均迭代次数(超过100个种子输入),以找到这些LeNet-1变体与原始版本之间的第一个差异诱导输入。总体而言,本文发现DeepXplore非常擅长发现差异很小的DNN之间的差异(仅失败一次,如表12所示)。随着差异数量的减少,找到引起差异的输入的迭代次数增加,即在具有较小差异的DNN之间找到差异引起的测试变得越来越困难。
7.3 Improving DNNs with DeepXplore
本节中将演示DeepXplore生成的错误诱导的输入的其他两个应用:扩充训练集,然后提高DNN的准确性,并检测可能损坏的训练数据。
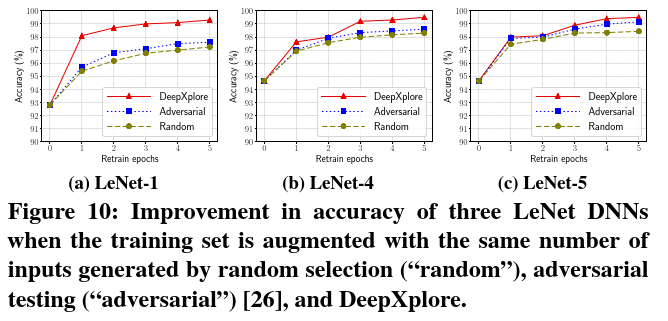
Augmenting training data to improve accuracy 本文使用DeepXplore生成的错误诱导输入来扩充DNN的原始训练数据,以重新训练DNN来修复错误的行为,从而提高其准确性。请注意,修复DNN的对抗性输入行为也采用了这种策略,但是主要区别在于,对抗性测试需要手动标记,而DeepXplore可以采用多数投票来自动为生成的测试输入生成标签。请注意,基本假设是大多数DNN做出的决定更可能是正确的。
为了评估这种方法,本文如表1所示训练了LeNet-1,LeNet-4和LeNet-5,其中包含60000个原始样本。通过添加100个新的错误诱发样本并通过5个epoch来重新训练DNN,进一步扩充了训练数据。本文的实验结果(比较三种方法,即随机选择(”random”),对抗性测试(”adversarial”)和DeepXplore)显示在图10中。结果表明,相比于对抗性和随机扩充,DeepXplore的平均准确性提高了1-3%。
Detecting training data pollution attack 作为DeepXplore的另一个应用,本文通过在两个LeNet-5 DNN上进行的实验演示了如何将其用于检测训练数据污染攻击:一个训练了MNIST数据集中的60000个手写数字,另一个训练了同一个但受人为污染版本的数据集,其中30%最初标记为数字9的图像被误标记为1。本文使用DeepXplore生成错误诱导的输入,这些输入分别由LeNet-5 DNN的未污染版本和受污染版本分类为数字9和1。然后,本文根据结构相似性在训练集中搜索与DeepXplore生成的输入最接近的样本,并将其识别为污染数据。使用此过程,DeepXplore能够正确地识别95.6%的污染样品。
8 Discussion
Causes of differences between DNNs 相同输入的两个DNN之间的预测差异背后的根本原因是其决策逻辑/边界的差异。如第2.1节所述,DNN的决策逻辑由多种因素决定,包括训练数据,DNN架构,超参数等。因此,这些因素选择上的任何差异都将导致最终DNN的决策逻辑发生细微变化。正如我们在表12中凭经验证明的那样,两个DNN的决策边界越相似,找到引起差异的输入就越难。但是,我们测试的所有实际DNN往往都存在显着差异,因此DeepXplore可以有效地发现所有测试的DNN中的错误行为。
Overhead of training vs. testing DNNs 在大型现实世界的DNN的预测/梯度计算与训练之间存在明显的性能不对称。例如,在ImageNet数据集竞赛中对120万张图像训练如VGG-16(本文中已测试的DNN之一)这样的最新DNN在单个GTX 1080 Ti GPU上可能需要长达7天的时间。相比之下,同一GPU上的预测和梯度计算每个图像总共花费约120毫秒。大型DNN的训练和预测之间如此巨大的性能差异,使DeepXplore特别适合测试大型,预训练的DNN。
Limitations DeepXplore采用了软件分析中的差分测试技术,因此继承了差分测试的局限性。本文在下面简要总结它们。
首先,差分测试需要至少两个具有相同功能的不同DNN。此外,如果两个DNN仅略有不同(即,有一些神经元上的不同),则DeepXplore将比DNN之间显著不同花费更长的时间才能找到差异诱导输入(如表12所示)。但是,评估表明,在大多数情况下,对于给定的问题,多个不同的DNN很容易获得,因为开发人员经常定义(define)和训练自己的DNN以进行自定义(customization)和提高准确性。
其次,只有至少一个DNN产生与其他DNN不同的结果时,差分测试才能检测到错误行为。如果所有测试的DNN均犯相同的错误,则DeepXplore无法生成相应的测试用例。但是,由于大多数DNN都是独立构建和训练的,因此本工作发现这在实际中并不是一个严重问题,所有DNN犯相同错误的几率都很低。
9 Related Work
Adversarial deep learning 最近,机器学习的安全性和隐私性方面问题已经引起了机器学习和安全社区研究人员的极大关注。这些工作中的许多都表明,对于DNN正确分类的原始输入图像,可以通过对其进行微小扰动来欺骗DNN,即使修改后的图像在外观上与原始图像在人眼上几乎无法区分。
对抗性图像展示了DNN的一种特殊类型的错误行为。但是,它们有两个主要局限性:
- 它们的神经元覆盖率低(类似于图9所示的随机选择的测试输入),因此,与DeepXplore不同,它不能暴露不同类型的错误行为;
- 对抗性图像生成过程固有地仅限于使用微小的,不可检测的扰动,因为任何可见的变化都需要人工检查。DeepXplore通过使用差分测试绕过此问题,因此可以扰动输入以创建许多现实的可见差异(例如,不同的光照,遮挡等),并在这些情况下自动检测DNN的错误行为。
Testing and verification of DNNs 评估机器学习系统的传统方式主要是根据来自手动标记的数据集的随机抽取的测试输入来衡量其准确性。一些机器学习系统(例如自动驾驶汽车)利用临时的无指导模拟(ad hoc unguided simulation)。但是,在不了解模型内部的情况下,此类黑盒测试范式无法找到不同的导致错误行为的极端情况。这一发现启发了一些研究人员试图提高DNN的鲁棒性和可靠性。但是,所有这些项目仅专注于对抗性输入,并依赖于人工提供的正确标注(ground truth)标签。相比之下,本文的技术可以以全自动方式系统地测试DL系统针对各种缺陷的鲁棒性和可靠性,而无需任何人工标记。
最近的另一项工作探索了针对不同的安全特性(safety properties)正式验证(formally verify)DNN的可能性。这些技术都无法很好地扩展,以发现有趣的违反了real-world DNN安全属性的行为。相比之下,DeepXplore可以在大型,最新的DNN中发现有趣的错误行为,但不能提供有关特定DNN是否满足给定安全性的任何保证。
Other applications of DNN gradients 过去,梯度已用于可视化DNN的不同中间层的激活,以执行诸如对象分割,两个图像之间的艺术风格转换等任务。相反,本文应用梯度上升来解决联合优化问题,该问题使神经元覆盖率和被测DNN之间的差异行为数量最大化。
Differential testing of traditional software 差分测试已广泛并成功用于测试各种类型的传统软件,包括JVM,C编译器,SSL/TLS认证验证逻辑,PDF查看器, 太空飞行软件,移动应用程序和Web应用程序防火墙。
与传统软件相比,将差分测试应用于DNN的关键优势在于,找到大量差异诱导输入同时最大化神经元覆盖范围的问题可以表示为定义明确的联合优化问题。而且,可以利用DNN相对于输入的梯度来利用梯度上升有效地解决优化问题。
10 Conclusion
本文设计并实现了DeepXplore,这是第一个用于系统测试DL系统并自动识别错误行为的白盒系统,无需手动标记。本文引入了一种新的度量标准,即神经元覆盖率,用于测量DNN在一组输入中行使了多少条规则。DeepXplore执行梯度上升以解决联合优化问题,该问题使神经元覆盖率和潜在错误行为的数量最大化。DeepXplore能够在由五个real-world数据集训练的15个最新DNN中发现数千种错误行为。
个人想法
变异方式:文中有一些细节没写全,从给的图例能看出,分别模拟三种自动驾驶摄像头可能遇到的问题——光照(修改全局亮度[有待考证,仅从图例上看确实同时只能对整个图片作亮度变化]),遮挡(随机颜色像素点填充单个小矩形),灰尘(多个黑色小矩形)。首先,文中给的例子,这三种变异方式是独立实施的,并没有看到多种变异方式同时施加与同一张图片中,具体得看源码;其次,虽然是模拟,但是这几种扰动太过幼稚,突发奇想,可以找找有没有别的AI技术,能够对图片施加更加真实又多样化的“扰动”。
Neuron Coverage:开山之作,但是后续他人工作对Neuron Coverage的评价不是很好,主要原因有:这个阈值是固定的,而且是整个DNN通用,但这对于确定“神经元是否激活“来说并不太精确。所以这上面的话需要找一个更灵活,更贴合DNN各个层特点的阈值设定方案。
差分测试:说不清这是优点还是缺点,因为本文的方案确实一定程度上不需要人工标记的工作量,并且可能实施更大破坏性的变化。但是考虑实际的测试场景,要想本工作跑起来,首先要找到至少3个DNN(只考虑差异性,2个DNN就能实施,但是考虑自动标记中采用”少数服从多数“原则,应该至少需要3个,本文测试都是3个DNN),但是假设我需要对模型A进行测试,那我先给它找相同定位,输入/输出类型格式相同的模型B,C进行差分测试,但是如果测试结果中,产生分歧/差异的都是B或C,而A并没有发生错误分类,那这次测试算是成功的吗?
漏报:少数服从多数的策略,必然存在漏报问题,即所有被测试DNN均判断错误,文中给出的观点是”概率太小,不作考虑“,有点道理,但是也存在隐患
输入类型:主要是图像,此方向的后续几篇工作,也基本都是图像的神经网络。一个原因是做图像简单。另一个原因,如果把模型测试扩展到音频识别的模型上去,简单的让模型分类出错,可能并不“interesting”。对图像识别来说,让模型分类出错,可能导致诸如自动驾驶判断错误,这对整个DL系统来说是“interesting”的;但对音频识别来说,通过类似对抗样本的方式,致使AI“听错字”,相比图像识别错误来说,没有价值,除非实现让VPA(Voice Personal Assistant)听错并有导向的识别成其他指令,这样比较有意义。
组会记录
- 如果超过50%的测试模型输出了错误的分类结果,那么该框架就会将这个输入打上错误的标签,影响准确性。
- 对模型A、B进行模型融合,新模型是否会继承A与B的缺陷?
- 使用梯度上升方法真的好吗?有更好的替代吗?或者梯度上升本身会有什么问题吗?
- Neuron Coverage阈值怎么确定?不同的激活函数会影响Neuron Coverage吗?——实验性、经验性确定。应该会影响,所以需要通过实验确定最佳的阈值。
- 超参数应该怎样设置?——实验性、经验性确定,调参。
- 使用小样本训练模型,是否会产生一些共性问题,类似“近亲繁殖”的概念?
- 能否用于模型后门检测?怎么检测?
- 本文题目叫“白盒”,是因为它是第一个提出白盒测试的工作吗?——不是